Using DuckDB to query beneficial ownership data in Parquet files

Open Ownership’s vision is that governments, businesses, and citizens can readily access and effectively use accurate, complete and high-quality data on the people who own or control companies.
To that end, our open source beneficial ownership data analysis tools help analysts, journalists and anyone wanting to examine and dive into beneficial ownership data published in line with the Beneficial Ownership Data Standard (BODS), the world's leading open standard for collecting and publishing high-quality beneficial ownership information.
The tools do this by converting BODS JSON files mapped from national beneficial ownership registers (Denmark, Slovakia and the UK) into a variety of formats including csv, Parquet, SQLite and PostgreSQL.
Increasingly, tools are being created to make it easier to use, query and process data files in formats such as Parquet without the need to install a database. One such tool is DuckDB, a fast and efficient online analytical processing structured query language (SQL) database management system, which only requires minimal setup.
To demonstrate the capabilities of DuckDB for querying beneficial ownership datasets, our team has created a reproducible data analysis notebook showing a number of queries which create data samples or list people who have direct beneficial ownership interests in a company.
This is an excerpt from the notebook:
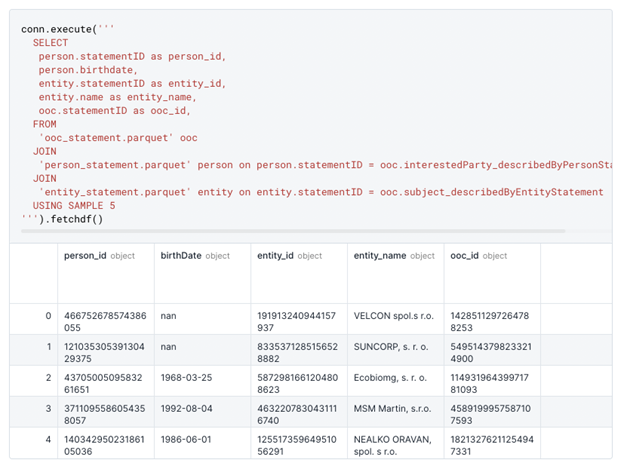
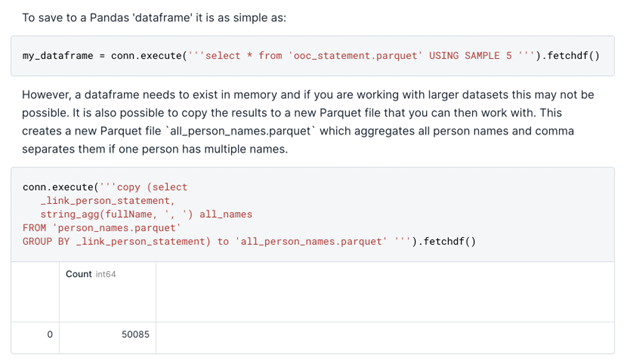
The notebook also shows you how to save query results as a Pandas dataframe, or as a new Parquet file, in order to reduce the size of the data you’re working with. This also allows you to carry out further data analysis or data science experiments.
Example: In this analysis notebook examining 2021 data from Latvia’s national beneficial ownership register, you can see how the data has been checked against the Open Ownership Principles. For example, we can consider the detail that is collected in the register, by querying the individual year of birth for all person statements collected. We see that most age ranges are in a realistic range and follow a realistic distribution, however the presence of some birth years after 2010 and in the future suggest that there may be verification or publishing issues.
For our example queries, we are using data from Slovakia’s Public Sector Partners Register, but this work could be repurposed to inspect any data source. You can read more on the public version of the notebook, or check out the code to see the work being done behind the scenes.
The open source code powering the tools website and the data processing tools is available on Github, and we also have information about further analysis notebooks and dashboards for BODS data on our website.
To share feedback about these tools, please raise issues on Github or connect with the data support team at Open Ownership via email at [email protected].


