Comprendre l’utilisation des données relatives à la propriété effective
Conclusions de l’étude : Vers un cadre permettant de mieux comprendre l’utilisation des informations relatives à la propriété effective
Les utilisateurs des informations relatives à la PE poursuivent des objectifs très variés, allant de l’identification et de la gestion des risques en tant qu’entreprise à la détection des conflits d’intérêts dans les marchés publics. Chaque utilisateur tente de répondre à des questions dans un but spécifique, y compris, par exemple :
- identifier une personne donnée soupçonnée de détenir et de bénéficier illégalement de certains biens ;
- identifier les résidents fiscaux nationaux susceptibles de recourir de manière abusive à des véhicules juridiques pour échapper à l’impôt ;
- identifier les liens entre les personnes politiquement exposées (PPE) et les entreprises qui opèrent dans des secteurs stratégiques et sensibles ;
- assurer la vigilance qui s’impose à l’égard des fournisseurs potentiels, des entreprises clientes ou de soumissionnaires ;
- surveiller les tendances en matière de concentration de la propriété pour aider à comprendre et à réguler la concurrence ;
- détecter les signaux d’alerte indiquant des risques de blanchiment d’argent et de corruption.
L’éventail des questions auxquelles les utilisateurs cherchent à répondre est révélateur de la diversité d’utilisation des données sur la PE. Même lorsque leur but est identique, les utilisateurs peuvent chercher à répondre à des questions distinctes. Ces questions ainsi que les informations que les utilisateurs considèrent en premier lieu, déterminent la manière dont les informations sur la PE sont utilisées.
Les deux sections qui suivent explorent les points communs et les différences entre les expériences et les besoins des utilisateurs dans le cadre du processus engagé pour répondre à leurs questions. La dernière section présente les enjeux pour les décideurs politiques et les organismes chargés de concevoir et d’administrer les registres de BE.
Expériences et besoins communs des utilisateurs
L’étude a identifié un grand nombre de points communs entre les besoins des utilisateurs associés à divers types d’utilisation. Ces expériences communes valident bon nombre d’éléments mis en lumière dans les Principes d’Open Ownership. [7] Notamment:
- bénéficier d’un accès effectif à des informations exploitables ;
- récupérer des informations pertinentes et exploitables ;
- comprendre les relations à travers les sujets d’une même source d’information et entre différentes sources ;
- bénéficier d’un niveau minimum d’exactitude pour pouvoir tirer des conclusions de façon assurée.
Bénéficier d’un accès effectif à des informations exploitables
Avant de pouvoir utiliser des informations relatives à la PE, il faut pouvoir y accéder. Cependant, les utilisateurs sont encore nombreux à être confrontés à d’importantes difficultés pour accéder aux données dont ils ont besoin. Malgré l’augmentation significative du nombre de juridictions qui mettent en œuvre des réformes en faveur de la TPE, il existe encore des divergences importantes entre les États en ce qui concerne la disponibilité et la qualité de l’information ainsi que les modalités d’accès. De ce fait, l’information n’est d’ailleurs pas toujours actualisée, quand elle n’est pas totalement inaccessible. Ces points ont été largement évoqués par les participants à l’étude. Ainsi, ce participant employé par une administration fiscale a par exemple insisté sur les avantages d’un accès direct à l’information est bénéfique pour lutter contre la fraude fiscale :
« Plus vous obtenez des preuves rapidement, plus vous êtes efficace. L’accès direct aux informations relatives à la PE permet un gain de temps conséquent. Sans accès direct, en tant qu’administrateur fiscal, vous devez écrire à une personne ou à une entreprise ou à la personne chargée du registre, qui disposent légalement d’une semaine pour fournir les renseignements. Sans réaction de leur part, nous pouvons alors envoyer un premier rappel. Puis un second. Si elles se contentent de fournir des informations partielles, elles peuvent également demander plus de temps pour les fournir en totalité. Ce n’est qu’à ce moment-là qu’interviennent les mesures répressives. Un processus qui peut facilement s’étendre sur plus de trois semaines. » [8]
Ces problèmes sont particulièrement prononcés lorsque les utilisateurs tentent d’accéder à des informations provenant d’une juridiction étrangère. Le manque d’informations disponibles sur les BE des véhicules juridiques étrangers demeure un obstacle important pour la plupart des types d’utilisation. Un journaliste d’investigation participant a expliqué : « Je travaille principalement sur des cas de fraude fiscale et de liens avec des paradis fiscaux. Tous les cas sur lesquels j’ai travaillé impliquaient des liens transnationaux. Il est inévitable de devoir consulter le registre d’un autre pays ». [9] Pourtant, les utilisateurs non gouvernementaux ne sont souven pas en mesure d’accéder à ces informations et bon nombre d’entre eux s’appuient en grande partie sur des sources en accès libre, comme la plateforme de données d’enquête Aleph de l’Organized crime and corruption Reporting Project (OCCRP), qui réunit plusieurs types d’informations en un même lieu. [10]
Un certain nombre de participants à l’étude ont également mentionné les difficultés rencontrées pour accéder aux informations sur la PE concernant des types particuliers de véhicules juridiques, comme les trusts et autres constructions juridiques, tant au niveau national que dans des juridictions étrangères. Ces véhicules juridiques ne sont pas toujours soumis à des exigences d’enregistrement et peuvent représenter des angles morts dans les réseaux de relations entre individus, véhicules juridiques et actifs (réseaux de BE). [11] Lorsqu’un enregistrement de l’entité est requis, les dispositions en matière d’accès peuvent différer et empêcher une utilisation efficace de l’information. Un participant à l’étude, qui utilise les informations relatives à la PE pour comprendre la propriété et le contrôle des terres, a expliqué : « C’est ici que la piste s’arrête. » [12]
Enfin, comme nous le verrons tout au long du présent rapport, dans de nombreux cas, les possibilités d’accès à l’information et de traitement des données sont telles qu’elles ne permettent pas aux utilisateurs de répondre à leurs questions. Les conclusions de l’étude suggèrent que les régimes d’accès fondés sur une catégorisation des utilisateurs sur la seule base de leur profession ou de leur secteur risquent de ne pas tenir compte des similitudes et des différences entre les différents types d’utilisation.
Bien que cette catégorisation puisse être utile pour réaliser une première cartographie des profils d’utilisateurs censés utiliser les informations relatives à la PE – conformément à ce qui a d’ailleurs été fait aux fins de la présente étude – et s’assurer que les informations relatives à la PE sont accessibles aux bonnes personnes, les conclusions de cette étude suggèrent que ces dispositions d’accès, dans la plupart des cas, ne répondent pas aux besoins des utilisateurs.
Récupérer des informations pertinentes et exploitables
Quel que soit leur but, les utilisateurs peuvent commencer leurs investigations soit sur la base d’informations concrètes spécifiques (par exemple, des informations sur un client, des listes de personnes sanctionnées, des informations sur des sociétés qui se positionnent sur un appel d’offres public), soit sur la base d’un ensemble initial de critères (tels que la nationalité des bénéficiaires effectifs ou le lieu d’incorporation d’une société).
L’étude a révélé que les participants utilisent une grande variété de critères pour interroger les données sur la PE. Par conséquent, tous les attributs (les champs de données) se rapportant à un sujet (individu, véhicule juridique ou actif) peuvent être pertinents pour aider les utilisateurs à répondre à diverses requêtes tout au long de leur parcours. Parmi les attributs jugés utiles par les participants à l’étude, les suivants ont par exemple été mentionnés : jour, mois et année de naissance ; adresse électronique et adresse postale des personnes physiques ; pays de résidence des personnes physiques ; adresse enregistrée des entreprises ; nature et niveau de participation au capital ; numéros d’identification, y compris fiscale ; adresse IP du déclarant ; nationalité(s) des personnes physiques ; et statut de PPE du bénéficiaire effectif. Le niveau d’utilité estimé pour chaque attribut dépendait largement du cas, de la requête et du contexte, et aucun attribut en particulier n’a été associé à des types d’utilisation ou des profils d’utilisateur spécifiques. La possibilité de consulter un registre sur la base des noms des bénéficiaires effectifs a été jugée extrêmement utile dans la quasi totalité des cas.
Un certain nombre de participants ont indiqué que les fonctionnalités de recherche limitées les empêchaient de consulter les registres de BE en utilisant des critères pertinents pour leurs pistes de questionnement. Certains ont mentionné utiliser des données en masse ou des API comme moyen alternatif afin de mener des recherches plus efficaces au sein des registres sur les BE ou d’améliorer les recherches en connectant les informations relatives à la PE directement à d’autres ensembles de données. [13] Cela suggère que l’amélioration de la fonctionnalité des registres et de la capacité de recherche peut conduire à une meilleure minimisation des données. Un fournisseur de services de données a expliqué : « Avec une API, vous pouvez rechercher une personne ou une entreprise et obtenir des informations supplémentaires à son sujet ». [14]
Bon nombre de participants à l’étude ont également mentionné avoir besoin de données historiques. Les renseignements sur les changements au fil du temps sont essentiels pour aider à détecter les risques, comme l’illustrent les citations des participants ci-après. Ainsi, des changements fréquents, des changements dont le calendrier est suspect ou des changements du bénéficiaire effectif déclaré à un membre de la famille peuvent constituer des signaux d’alerte utiles. Les données historiques sont également nécessaires pour surveiller les tendances au fil du temps. Deux participants à l’étude ont expliqué :
« Lorsque vous êtes sur une piste, elle est souvent basée sur des événements du passé. Vous regardez généralement qui détenait alors l’entreprise. Vous pouvez analyser les changements pour repérer des signaux d’alerte potentiels. Seule la consultation des antécédents vous permet d’avoir une image complète. » [15]
« Les évolutions au fil du temps sont très importantes. Par exemple, si vous constatez la création soudaine d’un trust, après qu’une personne a été sanctionnée, il peut s’agir d’un signal d’alerte. » [16]
Cela souligne à quel point il est important de s’assurer que les informations relatives à la PE divulguées soient actualisées et que leur exactitude soit régulièrement vérifiée, et que certaines données montrent clairement quels changements ont été apportés, quand et pourquoi, de manière à les rendre vérifiables pour les utilisateurs de données. [17] Le fait de disposer d’informations actualisées a été particulièrement apprécié notamment car d’autres sources d’information précieuses, telles que les fuites de données, ne fournissent qu’un arrêt sur image pour une période donnée. [18] Les participants à l’étude ont également déclaré apprécier le fait d’être avisés de toute évolution des informations concernant une entrerpise ciblée. Certains registres de BE proposent cette fonctionnalité. Certains prestataires commerciaux mettent en lien les données sur la PE avec d’autres sources d’information, élargissant ainsi la gamme des signaux d’alerte pour les utilisateurs (voir, par exemple, l’Encadré 2). [19]
À un niveau plus élémentaire, les utilisateurs ne savent pas nécessairement où trouver les informations qu’ils recherchent au sein des registres de BE de diverses juridictions. [20] Lorsque les archives sur la PE sont accessibles uniquement sur demande, les utilisateurs ne savent pas nécessairement si un registre contient des informations pertinentes tant que la requête n’a pas été satisfaite. Lorsque les informations relatives à la PE sont directement accessibles aux utilisateurs, le fait que ceux-ci ne connaissant pas la langue ou l’autorité responsable du registre a été signalé comme un obstacle par certains. Comme l’a expliqué une participante à l’étude : « Parfois, je veux vérifier le registre de BE d’une juridiction donnée, mais comme il n’a pas été conçu dans ma langue je ne suis pas toujours sûre de savoir si j’accède au registre officiel ou s’il s’agit d’une plateforme privée qui se contente de résumer les informations présentées dans les registres officiels ». [21]
Les outils qui favorisent une bonne orientation vers ces ressources peuvent être utiles pour surmonter ces obstacles. Open Ownership a récemment testé cet aspect en mettant au point un prototype de plateforme de recherche unique utilisant les API de registres de BE dans le but d’orienter les utilisateurs vers les supports susceptibles de contenir les informations recherchées au sujet des entreprises ou des individus visés. Après avoir testé le prototype avec un groupe défini d’utilisateurs, il a été constaté que cet outil pouvait aider les utilisateurs à trouver des informations dont ils ignoraient l’existence, tout en leur permettant de récupérer ces informations plus rapidement. Toutefois, l’outil ne répondait pas à bon nombre d’autres besoins identifiés dans le cadre de cette étude. [22]
Comprendre les relations à travers les sujets d’une même source d’information et à travers différentes sources
Dans la grande majorité des cas, les informations relatives à la PE ne sont pas utilisées de manière isolée. Elles comptent parmi les nombreuses sources d’information qui aident les utilisateurs à trouver des réponses à leurs questions et à avoir confiance dans leurs conclusions. La plupart des types d’utilisation s’appuient sur un processus consistant à établir des relations entre les sujets au sein de différentes sources d’information sur les BE et autres types d’ensembles de données (comme les registres d’entreprises et d’actifs, les listes de PPE et de sanctions), généralement en recoupant plusieurs juridictions (voir l’Encadré 5). Cette pratique répond à la majorité des besoins des utilisateurs, comme le confirme un participant à l’étude travaillant pour un prestataire commercial qui s’efforce d’offrir cette option à ses utilisateurs :
« Nous avons élaboré des outils de cartographie pour des clients comme les journalistes d’investigation, les fournisseurs de services de données, les autorités chargées de l’application de la loi et les institutions financières ; il s’agit avant tout de leur permettre de combiner un ou plusieurs ensembles de données pour obtenir les informations recherchées. Ce système est très répandu à travers le monde ... Les données sur les bénéficiaires effectifs sont essentielles pour établir un lien entre un client et une entreprise ou une personne morale et d’autres entités. » [23]
Ce processus nécessite une résolution d’entités ainsi que des moyens d’identifier de manière unique les individus et les véhicules juridiques. La résolution d’entités s’entend du processus qui consiste à déterminer si plusieurs enregistrements concernant un sujet (par exemple, des individus, des véhicules juridiques ou des actifs) font référence au même sujet ou à des sujets différents. La vérification de l’identité renvoie au processus consistant à déterminer à quels individus ou véhicules juridiques du monde réel correspondent ces enregistrements. Bien qu’il s’agisse de processus distincts, la vérification de l’identité peut permettre d’aboutir à la résolution d’une entité.
La résolution des entités est presque toujours nécessaire lorsque plusieurs sources d’information sont utilisées (voir la Figure 2), et parfois nécessaire pour une même source d’information (voir la Figure 1), en fonction des informations fournies. Il s’agit généralement de comparer un certain nombre de points de données ou d’attributs d’un sujet dans un enregistrement pour voir s’ils coïncident. Dès lors que les sujets peuvent présenter des attributs identiques ou très similaires (tels que des noms), des attributs supplémentaires peuvent permettre de confirmer avec certitude si deux enregistrements font référence au même sujet ou à des sujets différents. Certains attributs (tels que les identifiants) permettent d’aborder la résolution d’entités avec plus d’assurance que d’autres. En règle générale, plus un nombre important d’attributs coïncident, plus la résolution de l’entité est fiable. Les registres fournissent des quantités variables d’informations qui peuvent être utilisées à cette fin, ce qui signifie que différents niveaux de ressources sont nécessaires pour effectuer la résolution d’entités (voir l’Encadré 1). Certains registres sur les BE, comme le Central Business Register (CVR) au Danemark, identifient de manière unique les individus à l’aide d’un identifiant spécifique au registre.
Figure 1. Résolution d’entité au sein d’une source d’information unique
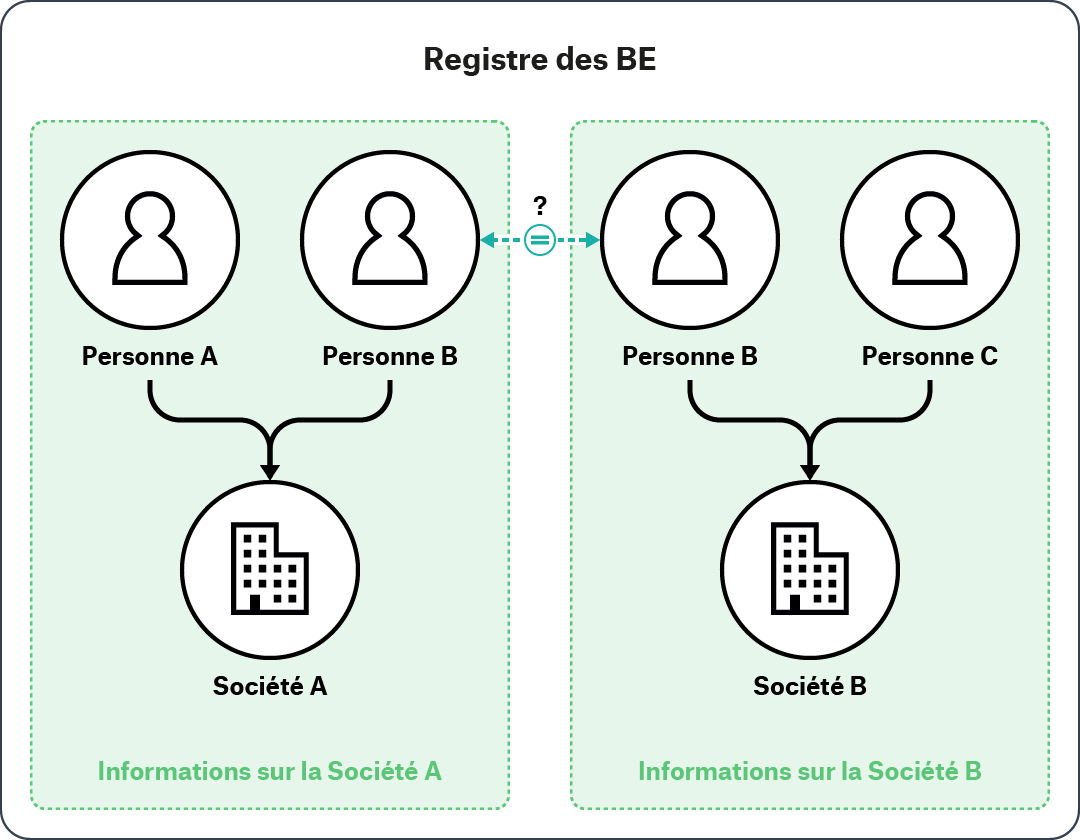
Dans cet exemple, un utilisateur peut rechercher la Société A dans un registre de BE. L’utilisateur voit que la Société A est liée aux Personnes A et B. L’utilisateur voit par la suite que la Personne B semble également avoir un lien avec la Société B, qui à son tour est liée à la Personne C. Pour procéder à un examen approfondi de la Société A, l’utilisateur peut avoir à déterminer si la Personne B citée dans les informations déclarées par la Société A se réfère à la même Personne B que celle qui est citée dans les informations déclarées par la Société B.
Figure 2. Identifier les relations et résoudre les entités entre les sources d’information
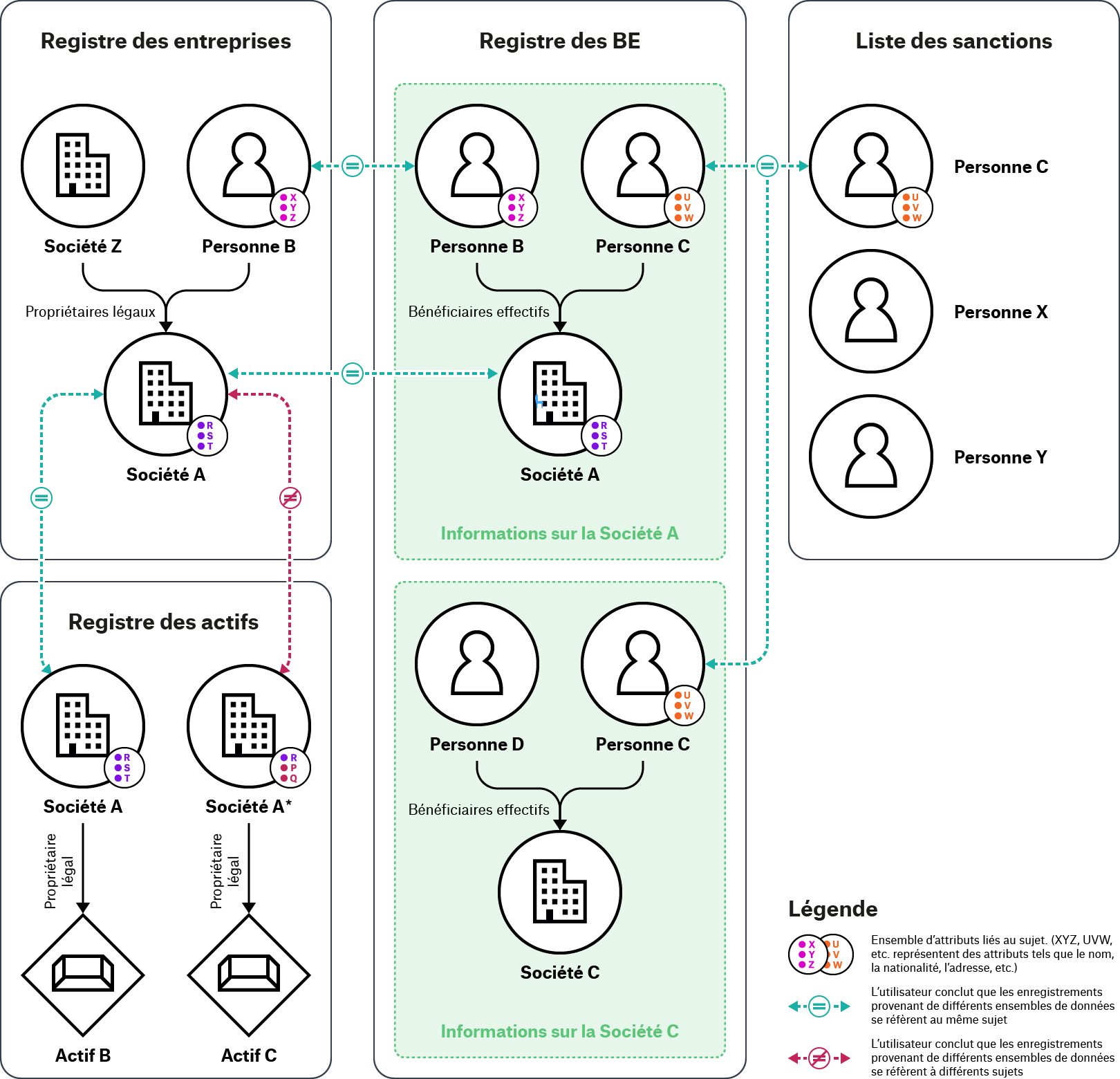
Dans cet exemple, pour procéder à l’examen nécessaire sur la Société A et les sujets qui lui sont associés, l’utilisateur doit croiser les informations contenues dans le registre des entreprises avec celles qui figurent dans le registre des BE, dans le registre des actifs et dans la liste des sanctions. L’utilisateur vérifie les informations relatives à la Société A dans les registres de cette Société et le registre des BE et constate que la Personne B est répertoriée en tant que propriétaire légal de la Société A dans le registre des entreprises et en tant que bénéficiaire effectif de la Société A dans le registre des BE. Pour déterminer si les enregistrements relatifs à la Personne B dans chaque registre se réfèrent aux mêmes individus ou à des individus différents, l’utilisateur vérifie si les attributs enregistrés à leur sujet dans différents registres ont la même valeur. L’utilisateur conclut que les enregistrements concernant la Personne B dans ces deux registres renvoient à la même personne lorsque des attributs suffisants ou spécifiques concernant leurs enregistrements coïncident. L’utilisateur répète la même procédure pour croiser les enregistrements concernant la Personne C dans les déclarations de BE des Sociétés A et C contenues dans le registre des BE, et dans la liste des sanctions. L’utilisateur consulte également le registre des actifs et identifie deux enregistrements au sujet de la Société A avec une orthographe légèrement différente pour la Société A (A et A*). Pour vérifier si ces enregistrements renvoient à la même Société A ou à une Société A distincte répertoriée dans le registre des entreprises et le registre des BE, l’utilisateur répète le même processus et conclut que la Société A du registre des entreprises et la Société A du registre des actifs représentent une seule et même entité. Cependant, étant donné que deux des attributs de la Société A* sur le registre des actifs ne coïncident pas avec les attributs de la Société A, l’utilisateur conclut que la Société A* renvoie à une société différente.
Encadré 1. Résolution d’entités dans le registre des bénéficiaires effectifs du Royaume-Uni [24]
La surveillance et la gestion des risques liés à la concentration de la propriété sont un sujet de préoccupation pour les autorités de réglementation de la concurrence, telles que la Competition and Markets Authority (CMA) au Royaume-Uni. La CMA utilise les informations relatives à la PE du registre des BE du Royaume-Uni pour analyser la concentration de la propriété dans des secteurs spécifiques une fois que la propriété et le contrôle communs ont été pris en compte.
Toutefois, les informations fournies par le RoyaumeUni ne sont pas suffisantes pour permettre de déceler aisément si les enregistrements concernant des individus se rapportent à ces mêmes personnes ou à des personnes différentes. Selon la CMA : « Les données disponibles dans [le registre des BE du Royaume-Uni] ne contiennent pas d’identifiants uniques pour les personnes physiques ou morales enregistrées en tant que [bénéficiaires effectifs]. Par conséquent, les données ne permettent pas de comprendre aisément si une personne ou une entité contrôle plusieurs entreprises ». [25]
Aux fins de la résolution des entités, la CMA doit alors se baser sur les attributs personnels (tels que nom, date de naissance et nationalité), ce qui requiert d’importantes ressources pour un résultat moins fiable.
Identifiants fiables
L’utilisation d’identifiants fiables dans différentes sources de données permet de procéder à la résolution d’entités ainsi qu’à la vérification de l’identité. Un identifiant fiable s’entend d’un numéro ou code de référence unique qui reste inchangé au fil du temps. [26] À titre d’exemple, on considère comme des identifiants fiables les identifiants délivrés aux particuliers par des instances gouvernementales faisant autorité, comme les numéros de passeport et de carte d’identité nationale, les numéros de sécurité sociale et les numéros d’identification fiscale (NIF). Pour les entreprises, les exemples incluent les numéros d’enregistrement ou de constitution des entreprises, les NIF ou les LEI. [27] Certains participants ont souligné l’importance de la confiance à l’égard de l’organisme qui fournit ces identifiants. Le secteur financier inclut ainsi un certain nombre de normes ISO qui recommandent des identifiants spécifiques. Les acteurs de l’industrie ont par exemple plaidé pour l’inclusion du LEI au titre des données exigées dans le cadre de la norme ISO 20022 relative aux paiements transfrontaliers. [28] « Le fait de rendre la divulgation du LEI obligatoire lorsqu’il est disponible au titre de l’ISO 20022 va s’avérer particulièrement utile dans le domaine des sanctions, car cet identifiant est considéré comme une source fiable, » a expliqué un expert du secteur. [29] Toutefois, ces données font encore défaut dans de nombreuses sources d’information (registres fonciers et données sur les marchés, par exemple). Un participant qui étudie les indicateurs des risques de corruption explique :
« La plupart des ensembles de données associés aux marchés publics ne comportent pas d’identifiants d’entreprise fiables, ou présentent une couverture incomplète, si bien qu’il est difficile de les faire coïncider avec les ensembles de données sur la PE. C’est peut-être l’une des principales raisons pour lesquelles les données sur la PE ne sont pas utilisées à l’heure actuelle dans le cadre de la commande publique. » [30]
Résolution d’entités pour les personnes physiques
Dans le cas des personnes physiques, la résolution d’entités est un exercice particulièrement difficile en raison de la nature sensible des identifiants fiables, qui touchent à la vie privée des personnes (par exemple, les numéros de carte d’identité nationale et de sécurité sociale). Rares sont les registres qui déterminent si des enregistrements relatifs à un sujet renvoient bien à un même sujet, ou à des sujets différents, ou qui fournissent suffisamment d’informations pour permettre aux utilisateurs d’effectuer cette recherche aisément et avec assurance, par exemple en fournissant des identifiants spécifiques aux registres (voir l’Encadré 5). Les prestataires commerciaux tentent de résoudre ce problème à l’aide de solutions technologiques qui permettent de vérifier numériquement l’identité des entreprises et des individus. [31] L’UE travaille sur des solutions harmonisées, telles que le portefeuille européen d’identité numérique. [32] Cependant, dès lors que ces solutions n’en sont encore qu’au stade du développements, les utilisateurs doivent pouvoir accéder à des alternatives.
Lorsqu’un même identifiant n’est pas utilisé dans plusieurs ensembles de données, les utilisateurs ont besoin d’attributs supplémentaires pour obtenir un niveau de confiance suffisant pour désambiguïser les enregistrements concernant les personnes physiques (par exemple, les informations personnelles telles que le nom complet, la date de naissance, la nationalité, le numéro de téléphone, etc.). Plus le nombre d’attributs à mettre en comparaison est important, plus l’utilisateur peut être confiant dans ses conclusions. Souvent, ces attributs supplémentaires sont nécessaires en présence d’un manque d’identifiants fiables pour les individus. Un participant a noté ce qui suit : « Il y a beaucoup de John Smiths dans le monde. Affiner la recherche au maximum (en déterminant par exemple jusqu’à son jour de naissance plutôt que de se contenter du mois et de l’année de naissance) sera d’autant plus utile. Et vous réduirez ainsi de façon considérable le traitement des données et le temps d’investigation. » [33] Si la résolution d’entités est déjà effectuée au sein même du registre et que ces derniers publient des identifiants pour les personnes physiques, cela réduira les obstacles à l’utilisation des données. Cela rendra probablement inutile d’accéder à et de traiter autant d’attributs différents pour les personnes physiques. Mais comme ces identifiants sont susceptibles de revêtir un caractère national ou propre à un registre, des attributs supplémentaires pourront tout de même être nécessaires lorsque plusieurs sources d’information sont utilisées.
Informations structurées, standardisées et interopérables
Un certain nombre de participants à l’étude ont également signalé des difficultés à traiter et à analyser l’information provenant de sources variées en raison des différents formats de données utilisés. Il est nécessaire de disposer de données structurées et davantage standardisées, comme l’indique ce participant travaillant dans le domaine des marchés publics :
« Le fait de disposer de normes bien plus claires sur la façon dont les noms, les dates de naissance, etc. sont structurés, et sur l’utilisation des identifiants, faciliterait et simplifierait grandement le processus visant à faire coïncider et relier les noms. » [34]
Lorsque les sources d’information sont convenablement structurées sous forme de données et comprennent des identifiants fiables, l’information est plus interopérable. Cela facilite son utilisation et permet de l’intégrer plus aisément dans d’autres systèmes, comme le montre le recours à des services de données commerciaux (voir l’Encadré 2). Le manque de standardisation dans la manière dont l’information est structurée peut compliquer la tache des utilisateurs qui s’efforcent de comprendre les réseaux de BE transnationaux, comme l’explique ce journaliste européen qui enquête sur des cas de fraude fiscale :
« À l’heure actuelle, l’un des principaux obstacles est le manque d’harmonisation, de transparence et de disponibilité des informations sur les BE dans les différents pays d’Europe. Nous avons avant tout besoin d’une plus grande coopération entre les pays. Des institutions régionales telles que l’UE pourraient appuyer le développement de registres centralisés fondés sur des normes communes. » [35]
Le niveau d’exploitabilité des informations provenant de sources distinctes dépend également des connaissances et des ressources des utilisateurs. Ainsi, un participant à l’étude travaillant pour une organisation non gouvernementale (ONG) a expliqué l’importance des compétences en analyse de données dans le contexte de l’utilisation d’informations provenant de divers ensembles de données. Il a expliqué : « Une grande partie des informations est encore stockée dans des PDF et les data scientists consacrent beaucoup de temps à des opérations manuelles. La démarche mobilise d’importantes ressources lorsqu’il s’agit de grands ensembles de données qui contiennent des millions d’enregistrements. C’est le cas par exemple lorsqu’il s’agit de mettre en correspondance des entités à partir de divers jeux de données répertoriant des biens immobiliers et de registres des propriétaires d’entreprises. » [36] De nombreux utilisateurs recoupent les informations en s’appuyant sur des ensembles de données à caractère commercial qui sont gérés par des fournisseurs privés (Encadré 2).
Utilisateurs de données intermédiaires
Face à ces défis, beaucoup d’utilisateurs s’appuient sur des intermédiaires, dont l’implication est décisive pour lever les barrières à l’utilisation des données (voir l’Encadré 2). Toutefois, certains obstacles pratiques entravent également l’accès aux ensembles de données à caractère commercial. Les grandes banques, par exemple, qui effectuent régulièrement des contrôles de vigilance à l’égard de centaines de milliers de clients, peuvent avoir la capacité et les ressources financières nécessaires pour utiliser et intégrer des solutions commerciales dans leurs propres systèmes, alors que les départements des petites banques n’ont peut-être même pas accès aux moyens de paiement nécessaires pour se procurer ces services. [37] Cela peut également s’appliquer à certains utilisateurs gouvernementaux. Les participants à l’étude issus de la société civile ont expliqué que les organisations à but non lucratif ne peuvent pas toujours se permettre ces services, mais certaines le font. [38] Les utilisateurs gouvernementaux ont également indiqué apprécier le caractère publiquement accessible des registres de BE, qui leur permettent un accès libre et direct aux informations provenant d’autres juridictions. L’accès du public à une information structurée est donc associé à des gains d’efficacité, même pour les utilisateurs dont le droit d’accès est sécurisé. Un participant à l’étude actif dans le domaine des marchés publics a expliqué :
« Tout ce qui est international est commercial. ... Du point de vue du temps consacré et de l’argent économisé en accédant à chaque registre et en procédant à des intégrations, il est probablement plus logique de payer pour un service commercial. … Mais l’open source créerait des économies à plus long terme pour les gouvernements. » [39]
Encadré 2. Combler les lacunes actuelles en matière d’accès et de traitement de l’information sur les bénéficiaires effectifs : le rôle des intermédiaires de données
Les intermédiaires fournissent des données (par exemple, combinées, nettoyées et structurées) et des services (par exemple, plateformes d’utilisation des données et outils sur mesure) pour aider les utilisateurs finaux à atteindre leurs objectifs. Ils aident à surmonter les défis en matière d’accès et d’utilisation des registres de BE. [40] Les intermédiaires de données sont un élément crucial de l’écosystème de l’utilisation des données. Leur travail consiste souvent à combiner des informations sur la PE provenant de différentes juridictions et avec d’autres types d’informations. Il implique généralement de procéder à la résolution d’entités et d’ajouter des attributs aux sujets visés (comme des informations sur l’insolvabilité pour les entreprises ou des informations défavorables dans les médias pour les particuliers). L’on peut citer ici l’exemple des fournisseurs commerciaux qui nettoient et regroupent les données de diverses sources de données, y compris les registres de BE et les fournisseurs de services tels que la résolution d’entités, ainsi que les organisations sans but lucratif qui créent des outils publics permettant de relier et faire coïncider les informations sur la PE avec d’autres ensembles de données.
Les services fournis par les intermédiaires comprennent également la mise à disposition d’informations historiques sur les BE lorsque celles-ci n’apparaissent pas dans un registre ou la possibilité de rechercher des informations sur la base de critères supplémentaires. Ils permettent également d’éviter le coût découlant de l’utilisation d’informations dans différents formats. Même lorsque ces services sont gratuits, il faut payer pour configurer un nouveau format de manière à le rendre aisément exploitable dans les systèmes locaux. Les prestataires commerciaux utilisent des informations provenant de sources gouvernementales et s’en remettent à celles-ci. Ces informations sont, à leur tour, largement utilisées par les gouvernements eux-mêmes. Certains font appel à des prestataires commerciaux pour conserver l’anonymat en matière d’accès à l’information.
Pour délivrer les services qui aident les utilisateurs finaux à utiliser les informations relatives à la PE, les intermédiaires de données ont souligné l’importance des API et des données en masse qui permettent d’intégrer les ensembles de données sur la PE dans les services proposés aux utilisateurs finaux. [41] Comme l’a expliqué un participant à l’étude : « Mon univers repose sur des données en masse. Les données en masse permettent de croiser les sources de données ». [42] Lorsque l’accès à l’information est fondé sur un intérêt légitime, des procédures d’accès efficaces sont requises. [43] Les participants à l’étude ont également rapporté que le recours à des identifiants uniques dans différents ensembles de données contribuent à rassembler les données. En ce qui concerne la résolution d’entités, les intermédiaires ont mentionné que tout ce qui peut les aider à relier des enregistrements sur des sujets à travers différentes sources d’information facilite leur travail. Ils ont également souligné qu’un plus grand nombre d’attributs permet un meilleur processus de résolution d’entités. [44] Un participant à l’étude, fournisseur de services de données, a expliqué :
« Notre algorithme est centré sur l’entité et fonctionne comme un enquêteur face à un registre. Plus le nombre de sources de données exploitées est important, plus il peut apprendre les attributs, comme une personne le ferait. L’algorithme centré sur l’entité utilisera tous les attributs que vous mettez à sa disposition. Plus vous fournissez de données, plus il est performant. Si vous avez attribué un paramètre spécifique à vos données, comme des identifiants d’entreprise, et que vous ajoutez une source de données qui inclut déjà ces identifiants, c’est formidable. Mais c’est rarement le cas malheureusement. » [45]
Interfaces de programmation d’application et données en masse
L’utilisation et la combinaison de sources d’information variées – et la résolution d’entités à travers ces différentes sources – peuvent s’avérer difficiles en l’absence d’un accès approprié aux API ou aux données en masse. Transparency International France et Anti-Corruption Data Collective ont par exemple réalisé une analyse de la propriété immobilière en France (voir l’Encadré 3) qui leur a demandé de parcourir cinq millions de pages web, soit plusieurs semaines de travail, et de mobiliser d’importantes ressources pour analyser et croiser les informations relatives à la PE et les informations cadastrales. Dans leur rapport, les deux organismes expliquent que le fait de ne pas pouvoir accéder aux données en masse a créé « un obstacle significatif... dans le suivi de la mise en œuvre des règles relatives à la propriété effective » et que « l’accès aux informations relatives à la propriété effective dans un format de données ouvert – ou encore mieux, l’accès via une API – permet aux acteurs clés d’utiliser plus efficacement les données ». [46] Cela laisse à penser que les registres dont l’accès se fait uniquement au travers de portails de recherche, et qui ne laissent par conséquent qu’une flexibilité limitée en termes de méthodes de recherche et de traitement de l’information, auront probablement moins d’impact que lorsque l’information est structurée et disponible en masse ou via des API. [47]
Comprendre les réseaux de bénéficiaires effectifs dans leur totalité
Les outils qui aident à comprendre les réseaux de BE dans leur totalité sont extrêmement utiles pour les utilisateurs, comme le décrit un participant : « Il ne s’agit pas seulement de visualiser, il s’agit aussi de rassembler toutes les informations ». [48] Un participant agent d’une autorité chargée de l’application de la loi a expliqué ce qui suit : « Avant le registre sur les BE, nous nous contentions d’utiliser le registre des entreprises pour consulter les informations sur les administrateurs [et] les actions et tenter de nous frayer un chemin à travers des structures d’entreprise complexes, étape par étape. Cela prenait beaucoup de temps ». [49] D’autres participants à l’étude ont mentionné être particulièrement intéressés par le réseau et les structures, plutôt que par les individus au bout de la chaîne. Ils ont déclaré utiliser l’information relative à la PE comme moyen à cette fin lorsque les données sur les actionnaires étaient de mauvaise qualité ou non disponibles. Un nombre limité de registres sur les BE collectent et partagent des informations sur les intermédiaires et les participations directes. Les informations sur les actionnaires sont très appréciées, mais elles sont rarement disponibles ou à jour. [50]
De plus, certains types d’utilisation impliquent d’essayer de comprendre les relations entre un grand nombre de véhicules juridiques, de personnes et d’actifs au fil du temps. Comme ces réseaux peuvent être difficiles à comprendre, les utilisateurs sont nombreux à souhaiter des outils qui permettent de visualiser ces relations. Aussi les utilisateurs ont-ils communément exprimé le besoin de structurer les données de manière à pouvoir aisément les transformer en formats graphiques.
Bénéficier d’un niveau minimum d’exactitude pour pouvoir tirer des conclusions de façon assurée
Dans bien des cas, l’utilisation des informations relatives à la PE consiste à croiser les informations provenant de sources de données distinctes, comme le font les personnes chargées des registres sur les BE lorsqu’elles vérifient l’exactitude des informations. Les informations sont utilisées dans le cadre du processus de vérification, tout comme de résolution d’entité : les attributs sur les sujets dans différentes sources d’information sont contrôlés les uns par rapport aux autres. Plutôt que d’établir s’ils portent sur le même sujet, l’objectif est de vérifier si l’une ou l’autre des informations est inexacte. Ce processus renforce la confiance dans les conclusions tirées à partir des informations en présence, mais nécessite également des ressources. Le contrôle des informations relatives à la PE par les utilisateurs répond à des finalités diverses, notamment :
- Une obligation légale de vérifier les informations en les confrontant à d’autres sources d’information. Les utilisateurs qui travaillent pour des institutions soumises à la législation anti-blanchiment de capitaux et pour certains organismes gouvernementaux sont souvent soumis à cette obligation. [51] Un participant du secteur financier a expliqué en quoi consiste ce processus à son niveau. Pour les nouveaux clients, il s’agit de s’assurer que l’identité d’une entité et des personnes qui lui sont associées est vérifiée à partir des renseignements et des documents qui accompagnent la demande. Cela inclut l’identité des bénéficiaires effectifs et les moyens par lesquels ils exercent leur propriété ou leur contrôle sur le véhicule juridique. Plusieurs sources d’information sont alors utilisées pour recouper les informations qui leur sont fournies. Le participant a expliqué que les informations relatives à la PE sont obtenues en trois étapes : premièrement, elles sont collectées par la banque ; deuxièmement, elles sont confrontées avec les informations figurant dans le registre national des BE et dans les registres d’autres juridictions ; et troisièmement, les informations relatives aux BE concernant d’autres sujets découverts dans le réseau qui n’ont pas été identifiés lors d’étapes antérieures sont confrontées avec les informations provenant d’autres registres. [52]
- Les participants représentant les autorités chargées de l’application de la loi ont expliqué que, dans les enquêtes sur la criminalité financière, certaines informations peuvent servir de renseignements mais ne répondent pas aux critères requis pour être présentées comme preuve devant les tribunaux. Ils croisent les informations provenant des diverses sources d’information, y compris les registres de BE, les moyens informels de transmission de renseignements, les informations bancaires et les demandes officielles d’informations par le biais de l’entraide judiciaire aux autorités étrangères. [53]
- L’atténuation des risques juridiques et réputationnels. Les participants représentant le secteur des médias ont par exemple mentionné combien il est crucial que les conclusions fondées sur les données puissent être corroborées par de multiples sources, en particulier lorsqu’elles peuvent impliquer des allégations contre des acteurs puissants. Comme l’a expliqué un participant à l’étude : « Des données inexactes peuvent vous coûter cher en tant que journaliste : elles peuvent vous conduire en prison ». [54]
- Les ONG qui mènent des recherches sur les sociétés extractives vérifient les informations par rapport aux connaissances locales afin de détecter les fausses déclarations et d’exiger des comptes de la part des sociétés extractives, par exemple, si une société relevant de leur périmètre d’action est soupçonnée d’avoir désigné un prête-nom comme propriétaire. [55]
L’étude a révélé que, bien que les utilisateurs vérifient les informations, ils n’exigent pas nécessairement qu’elles soient parfaitement d’exactitude. Les participants à l’étude, tant des médias que des autorités chargées de l’application de la loi, ont souligné la valeur des lacunes, des inexactitudes et des écarts dans et entre les informations trouvées dans diverses sources. Ainsi, une inexactitude dans un champ n’est pas nécessairement considérée comme compromettant la valeur de la déclaration de PE dans son ensemble, et peut même inciter à une enquête plus approfondie et à des vérifications croisées avec d’autres sources d’information. Un journaliste danois participant à l’étude a expliqué :
« Les données... ne sont peut-être pas toujours correctes à 100 %, mais même dans ce cas elles vous permettent de poser des questions décisives. … C’est un outil très important pour vérifier les faits ou commencer une enquête. » [56]
En outre, l’obligation de divulguer crée une responsabilité légale en cas de faux renseignements. Un participant représentant une autorité chargée de l’application de la loi a souligné que les sanctions liées à la fourniture d’informations inexactes sur la PE leur offrent également des possibilités accrues d’engager des poursuites contre les sujets de leurs enquêtes. [57]
Bien que des données inexactes ou manquantes puissent contribuer à déclencher des signaux d’alerte ou des enquêtes plus poussées, il est plus difficile de le faire en présence d’erreurs accidentelles systématiques. Comme l’a expliqué un participant à l’étude : « Si les mauvais champs sont utilisés – par exemple, un nom de société renseigné dans la case prévue pour le nom du propriétaire – il devient tout à coup très difficile de comprendre les données et de savoir s’il y a un propriétaire réel ». [58] Un autre participant a déclaré : « Vous vous heurtez parfois à des points de données manquants, à des enregistrements incomplets sur les PPE ou à des incohérences dans les modalités d’actualisation des informations sur les bénéficiaires effectifs sur les différentes plateformes. La participation des OSC [organisations de la société civile] offre un niveau de vérification, révélant des écarts qui pourraient autrement passer inaperçus ». [59] Indépendamment de la raison pour laquelle ils vérifient les données, tous les utilisateurs de données relatives à la PE doivent pouvoir compter sur un niveau d’exactitude de base afin de pouvoir formuler leurs conclusions avec une certaine assurance. Cela implique de veiller à ce que les informations soient régulièrement mises à jour.
Différents types d’utilisation et besoins des utilisateurs
Bien que les besoins des utilisateurs présentent de très grandes similitudes, l’étude a permis de relever certaines différences. Pour tester la première hypothèse, l’équipe de l’étude s’est interrogée sur la diversité d’utilisation des informations relatives à la PE (types d’utilisation) et a cherché à savoir si les besoins des utilisateurs différaient selon le type d’utilisation. Le cadre suivant a donc été établi, identifiant les différents besoins des utilisateurs sur la base des éléments clés suivants :
- la nature qualitative ou quantitative de la question posée par l’utilisateur ;
- l’échelle du traitement des données nécessaire pour répondre à la question, c’est-à-dire le nombre de sujets (par exemple, individus ou véhicules juridiques) qui intéressent les utilisateurs ;
- l’éntendue du traitement des données nécessaire pour répondre à la question, c’est-à-dire le nombre et la variété des connexions ou des relations entre différents éléments d’information nécessaires pour que les utilisateurs parviennent à leur conclusion ;
- la fréquence du traitement nécessaire pour répondre à la question.
Nature
La question d’un utilisateur peut être de nature quantitative ou qualitative.
- Questions quantitatives : ces requêtes portent sur des nombres ou des tendances. Les utilisateurs qui répondent à ces questions envisagent de quantifier quelque chose plutôt que d’identifier des personnes ou des véhicules juridiques donnés.
- Questions qualitatives : ces requêtes portent sur des attributs spécifiques de véhicules juridiques ou d’individus donnés, ou des deux. Dès lors, les utilisateurs devront probablement identifier ces véhicules et individus donnés.
Encadré 3. Exemples de types d’utilisation impliquant une question de nature quantitative
En 2023, Transparency International France et Anti-Corruption Data Collective ont examiné les informations relatives à la PE publiquement accessibles en France en les croisant avec les informations du cadastre dans le cadre d’une analyse de la propriété immobilière en France. Ils ont constaté que près de 71 % de l’ensemble des parcelles appartenant à des sociétés sont détenues de manière anonyme. [60] Avant eux, l’ONG Reporters sans frontières et l’institut universitaire français appelé Laboratory for Interdisciplinary Evaluation of Public Policies (LIEPP) avaient exploré la concentration de la propriété dans les secteurs des médias français et espagnols et publié un rapport indiquant que plus de la moitié de chaque secteur était contrôlée par des entreprises du secteur financier et des assurances, dont la structure d’actionnariat complexe rendait difficile l’identification des bénéficiaires effectifs.
Les utilisateurs dont les questions sont de nature quantitative sont susceptibles de pouvoir répondre à leur question au moyen de données pseudonymisées en utilisant des identifiants uniques à la place des noms de sociétés et de personnes. Ainsi, un utilisateur qui envisage d’évaluer la proportion d’entités juridiques dont le bénéficiaire effectif déclaré est mineur devra par exemple être en mesure d’accéder aux dates de naissance des bénéficiaires effectifs. Pourtant, dans cet exemple, l’utilisateur pourrait se contenter de traiter les dates de naissance sans avoir à identifier les individus.
La mise à disposition, a minima, d’un ensemble de données pseudonymisées par les décideurs politiques et les organismes chargés de l’administration des registres de BE peut permettre certains types d’utilisation des données. Cependant, les utilisateurs dont les requêtes sont de nature qualitative ne seront probablement pas en mesure de remplir leur tâche sans avoir à traiter des informations personnellement identifiables. Cela peut se produire, par exemple, lorsqu’un utilisateur souhaite effectuer un contrôle de vigilance à l’égard d’une entité juridique en tant que fournisseur potentiel, ou lorsqu’un utilisateur cherche à enquêter sur un individu ou un véhicule juridique donné soupçonné d’activités criminelles ou frauduleuses.
Échelle
La question d’un utilisateur déterminera l’échelle des informations à traiter pour y répondre – c’est-à-dire le nombre potentiel de sujets d’intérêt dans les informations traitées pour répondre à la question. Les premières informations utilisées influencent souvent cet aspect.
- Grande échelle : les utilisateurs peuvent (i) commencer avec une grande quantité d’informations (par exemple des listes d’entités ou d’individus), ou (ii) avoir à identifier des relations ou des tendances dans un registre de BE tout entier. La plupart des utilisateurs qui posent des questions quantitatives liées à des tendances nécessitent principalement un traitement à grande échelle. Cependant, les questions qualitatives peuvent également nécessiter un tel traitement. Généralement, dans le cadre d’un traitement à grande échelle, la nécessité de traiter les données manuellement deviendrait un obstacle sérieux compromettant la capacité de l’utilisateur à répondre à sa question. La conduite d’analyses à grande échelle nécessite des moyens de traiter aisément de grandes quantités de données. Le recours aux API et l’accès aux données en masse prennent ici toute leur importance (voir l’Encadré 4).
- Petite échelle : les utilisateurs opérant à cette échelle répondent souvent, mais pas exclusivement, à des questions qualitatives. Ils s’intéressent le plus souvent à un petit nombre d’entités ou de personnes données et à leurs attributs et sont souvent en mesure de traiter les données enregistrement par enregistrement sans que cela ne représente une charge excessive ou n’affecte leur capacité à répondre à leur question.
Encadré 4. Exemples et points de vue d’utilisateurs expérimentés dans le traitement de données à grande échelle
Des chercheurs de Central European University (CEU) ont étudié si les données relatives à la PE pouvaient être utilisées pour une évaluation quantitative et à grande échelle, des risques au sein des marchés publics. Dans le cadre de leurs travaux, l’équipe a analysé des ensembles de données portant sur les marchés et sur les BE pour six juridictions. Leur analyse a permis de valider des indicateurs spécifiques à chaque juridiction en matière de corruption et de blanchiment d’argent, à partir des données sur la PE en lien avec les marchés publics. [61] En plus de souligner la nécessité de disposer de données structurées avec un historique des modifications, les chercheurs ont également mis en lumière l’importance des données en masse et, idéalement, des API pour permettre ce type d’analyse. [62]
Les utilisateurs des autorités chargées de l’application de la loi, des autorités fiscales et de la société civile réalisent par ailleurs des analyses qualitatives à grande échelle dans le but de détecter et de surveiller divers types de risques. Deux représentants d’une autorité chargée de l’application de la loi et d’une administration fiscale d’Europe et d’Afrique ont expliqué :
« Nous injectons les données en masse de Companies House (le registre officiel des entreprises du Royaume-Uni) dans nos propres banques de données. Cette manière de procéder permet une analyse plus proactive et crée des possibilités d’investigation. En termes de capacité d’exploitation des données, vous pouvez rechercher des informations sur un grand nombre d’entreprises et identifier des liens qui ne sont pas d’emblée apparents qui ne sont pas d’emblée apparentes. » [63]
« Se pencher sur des personnes qui feraient n’importe quoi pour éviter de payer des impôts et sur lesquelles ils convient d’enquêter, c’est autre chose que de rechercher des tendances et d’identifier certains secteurs et profils à haut risque. ... En ce qui concerne les tendances et le profilage des contribuables, nous devons être en mesure de détecter des tendances suspectes. Par exemple, si la mention « nul » apparaît systématiquement dans une auto-déclaration ou si cette dernière inclut des changements dans la propriété légale et effective. » [64]
Le fait de pouvoir interroger de manière flexible un ensemble complet de données à l’aide d’une API favorise la démarche. Par exemple, un participant à l’étude a expliqué qu’il peut être utile de pouvoir trouver des informations sur toutes les entreprises dont l’administrateur est d’une nationalité donnée. [65] Ce qu’a confirmé un participant d’une administration fiscale, expliquant que les moteurs de recherche utilisés en interne au sein de son organisme leur permettent de définir des règles pour soutenir l’évaluation des risques et identifier les contribuables qui correspondent à un certain profil. Celui-ci explique : « Il est possible par example de demander à voir tout ce qui implique un changement de participation au capital ou qui inclut une déclaration de revenus nulle. Pouvoir en faire de même dans le cas des informations relatives à la PE permettrait d’ajouter davantage de critères déclencheurs et d’enrichir votre processus d’identification des risques. » [66]
Un autre participant à l’étude travaillant pour une CRF a mentionné la disponibilité des API comme un facteur clé pour faciliter leur travail, y compris par le biais du registre national des BE. Une longue liste d’autres organismes gouvernementaux et sources d’information avec lesquels la CRF est ont été citées. Par exemple, ces sources comprennent les douanes, l’identité nationale, la sécurité routière et la circulation, l’immigration, l’administration fiscale, la banque centrale, la commission des titres et de la Bourse, ainsi qu’un certain nombre d’organismes de réglementation, tels que l’agence de supervision du secteur immobilier. [67] Le fondateur d’une société de logiciels qui fournit des services de soutien aux acteurs de la lutte contre la criminalité financière a expliqué plus en détail : « L’intégration de données en masse produit beaucoup de valeur. Lorsque vous enrichissez vos propres données avec des données tierces, vous pouvez calculer les scores de risque et détecter les alertes sur l’ensemble des données ». [68]
Étendue
L’étendue du traitement des données renvoie au nombre et à la variété des connexions qu’un utilisateur doit identifier au sein d’une piste de questionnement. Cela peut aller de l’utilisation d’informations relatives à la PE à partir d’un registre de BE unique aux tentatives d’identification des connexions entre les sujets pour plusieurs sources de données. Ce paramètre peut être influencé par le type d’information que l’utilisateur exploitera en premier dans le cadre de son parcours d’utilisation des données.
- Les requêtes peuvent avoir une étendue limitée et ne nécessiter que des informations sur la PE provenant d’un seul registre de BE pour répondre à leur question. Cela peut inclure l’examen des relations entre un nombre limité de personnes différentes, ou entre différentes entreprises. Une étendue limitée peut rendre le traitement des données relativement simple. L’étude a toutefois révélé que seul un petit nombre de types d’utilisation sont concernés.
- Dans les vastes requêtes, les utilisateurs doivent identifier les relations entre plusieurs sujets. La requête peut ici concerner un seul registre de BE ou croiser des registres de BE distincts, et impliquer des ensembles de données supplémentaires (par exemple, marchés publics, listes de PPE, etc.) et d’autres sources d’information (telles que sites Web d’entreprises, sources médiatiques, etc.). L’étude a révélé que ce scénario représente la majorité des cas.
Sur ce spectre, les utilisateurs qui doivent procéder à un vaste traitement des données ont davantage besoin de mécanismes facilitant le processus d’identification des connexions entre les sujets (Encadré 5). L’investissement dans des mécanismes de soutien à la résolution d’entités et à la vérification d’identité prend ici toute son importance.
Encadré 5. Exemples et aperçus de types d’utilisation impliquant différentes étendues de traitement des données
Un locataire peut souhaiter identifier les bénéficiaires effectifs d’une entreprise propriétaire de son appartement. Aux États-Unis, les sociétés à responsabilité limitée dont les propriétaires sont anonymes sont couramment impliquées dans des cas de désinvestissements dans le logement, de mauvaises conditions de logement et de retards dans l’accès des locataires aux fonds mobilisés par les programmes du gouvernement. [69] Il s’agit d’une requête relativement simple dont l’étendue est limitée. L’utilisateur ne peut identifier qu’une seule ou quelques relations entre son propriétaire et les bénéficiaires effectifs.
Un utilisateur qui souhaite évaluer le niveau de conformité vis-à-vis des obligations légales de divulgation des BE pourra demander Combien de sociétés n’ont pas divulgué de bénéficiaires effectifs ? [70] Il s’agit d’une requête quantitative qui nécessite un traitement à grande échelle, mais dont l’étendue reste limitée.
En revanche, dans une affaire majeure de corruption et de vol d’avoirs, la CRF et les autorités chargées de l’application de la loi au Nigéria ont utilisé diverses sources d’information, notamment le registre des sociétés, le système de gestion de l’information sur les dossiers criminels, les renseignements en libre accès, les rapports d’institutions financières, les informations tirées de leur propre base de données et les canaux d’échange d’informations avec les CRF de plusieurs autres juridictions pour cartographier un réseau de personnes et de véhicules juridiques et identifier 1,7 milliards de dollars de fonds manquants. [71] L’enquête a nécessité une vaste étendue d’identification de relations entre les sujets et entre les sources d’information.
Fréquence
Les utilisateurs peuvent exiger le traitement des informations sur une base unique, récurrente ou continue :
- Dans le cas d’un traitement ponctuel, les utilisateurs doivent simplement répondre à leurs questions à un moment précis.
- Dans le cas d’un traitement récurrent ou continu, pour répondre à sa question, l’utilisateur doit traiter des informations de façon répétitive ou continue. Ainsi, pour générer une image actualisée et en temps réel du risque, le traitement des données sur la PE – et dans certains cas leur intégration – doit s’opérer sur une base continue (voir l’Encadré 6). En fonction de l’échelle de la requête, la démarche peut s’avérer impossible si le registre ne propose pas de fonctionnalités telles que les alertes automatisées, les API de streaming ou l’accès à des informations actualisée en masse.
Encadré 6. Exemples de types d’utilisation nécessitant une base continue
Des journalistes spécialisés en données et des chercheurs de Colombie, de Mongolie et du Nigeria ont combiné diverses sources d’information publique et élaboré des outils d’analyse dans une perspective de responsabilisation et de surveillance de l’industrie extractive. Le Mongolia Data Club a par exemple croisé des données sur la propriété légale et effective, sur les marchés publics et d’autres sources au sein d’une plateforme numérique visant à mieux comprendre les activités et les liens des fournisseurs d’entreprises publiques dans le secteur minier. [72] Les journalistes et les chercheurs ont utilisé leur formation et leurs outils pour explorer diverses questions, par exemple en interrogeant l’attribution de permis de transport de charbon de la Mongolie vers la Chine. [73] Les journalistes ont également étudié les entreprises détenues par les candidats aux élections nationales afin d’assurer un contrôle public et d’apporter un éclairage sur tout conflit d’intérêts potentiel. [74]
Au Nigeria, Directorio Legislativo s’est associé à l’organisation de la société civile BudgIT pour monter la plateforme Joining the Dots, qui combine les informations relatives à la PE, les listes de PPE et les informations sur les permis d’exploitation minière dans le but de surveiller les liens entre les personnalités politiques et les permis d’exploitation minière et, si nécessaire, déclencher des alertes de manière automatique et continue. [75]
Pour faciliter un contrôle public durable, les outils développés par le Mongolia Data Club et Directorio Legislativo nécessitent des mises à jour régulières ou continues des informations provenant de diverses plateformes publiques. Directorio Legislativo avait envisagé de mettre à jour sa plateforme sur une base semestrielle, mais les contraintes de capacité interne et l’indisponibilité d’une API de streaming ont fait obstacle à ce projet. Les contraintes étaient également dues à l’absence de données de meilleure qualité et plus normalisées à travers les différentes sources.
Pour les requêtes à plus petite échelle qui nécessitent une surveillance des informations sur une période donnée, les alertes automatisées se sont révélées utiles pour aider les utilisateurs à se tenir au fait des changements. Au Danemark, par exemple, les utilisateurs peuvent s’abonner aux notifications par e-mail et ainsi être informés de tout changement concernant la propriété et le contrôle d’une entreprise donnée. Cette fonctionnalité est très appréciée par les participants à l’étude qui travaillent dans les secteurs de du suivi des affaires et des enquêtes sur la criminalité financière. [76]
Types d’utilisation, profils d’utilisateur et parcours d’utilisation de données
L’étude a certes identifié des différences entre les types d’utilisation, mais les besoins qu’ils génèrent se recoupent souvent. En outre, les besoins des utilisateurs ne sont pas liés à des métiers en particulier. Certains ensembles de besoins sont fortement associés à la question particulière à laquelle un utilisateur cherche à répondre et les questions peuvent évoluer au fil des parcours des utilisateurs. Les questions peuvent recouper les profils d’utilisateurs, ce qui signifie que les informations relatives à la PE peuvent être utilisées de la même manière par différents profils d’utilisateurs. Par exemple, les utilisateurs représentant des organismes de réglementation de la concurrence, des ONG, des établissements universitaires, des journaux et des autorités chargées de l’application de la loi peuvent tous effectuer un traitement à grande échelle pour identifier les tendances et détecter et atténuer divers types de risques. De la même manière, les utilisateurs des médias, les équipes de vigilance à l’égard de la clientèle dans les banques, les ONG et les autorités fiscales et de lutte contre la corruption peuvent traiter les informations relatives à la PE à plus petite échelle pour répondre à des questions qualitatives axées sur des personnes ou des entreprises données. Par conséquent, pour comprendre l’utilisation des données, il est important de ne pas limiter la réflexion au cadre des professions. Différents profils d’utilisateurs peuvent réaliser un parcours commun. Par exemple, des responsables d’autorités chargées de l’application de la loi ont souligné à maintes reprises le rôle crucial des acteurs de la société civile dans la réalisation de leurs objectifs. « Nous recevons de nombreuses références de journalistes et d’organisations de la société civile. C’est très fréquent. Ils représentent une formidable source d’information. Ils peuvent découvrir des faits dont nous n’étions pas au courant dont nous n’avions pas conscience jusqu’ici, » explique un participant à l’étude. [77]
La section ci-dessus considère la question de l’utilisateur comme principal point d’analyse. Néanmoins l’étude a identifié de nombreux exemples dans lesquels les utilisateurs posent diverses questions à différents moments dans le temps. Ce participant à l’étude chargé de missions d’investigation pour le compte d’une organisation de la société civile a expliqué :
« Parfois, lorsque vous effectuez un traçage des actifs, vous entendez parler d’une personne et vous engagez alors des recherches à son sujet dans les données, alors que dans d’autres cas, vous pouvez parcourir toute une base de données afin de repérer des éléments suspects. Nous [parlons ici de] pêche à la grande canne et de pêche chalutière. » [78]
Un autre participant employé par une administration fiscale a mentionné un point similaire, expliquant que les activités de son bureau pouvaient aller de l’examen de personnes soupçonnées de fraude fiscale à l’identification de tendances et d’indicateurs de risques (voir l’Encadré 4).
La variété des questions que les utilisateurs peuvent chercher à aborder est très large et une petite modification de la question peut considérablement changer les besoins des utilisateurs. Deux questions qui apparaissent similaires peuvent générer des ensembles de besoins légèrement distincts pour y répondre (Encadré 6).
Par exemple, les besoins d’un utilisateur demandant Quel est le degré de concentration de la propriété au Danemark ? seraient différents s’il reformulait sa question ainsi : Quel est le degré de concentration de la propriété dans les entreprises danoises auxquelles des marchés publics ont été confiés ? Dans la première question, l’utilisateur aurait besoin de moyens de traiter une grande quantité d’informations ainsi que d’identifiants uniques pour les individus, mais n’aurait pas nécessairement besoin de multiples sources d’information. Dans la deuxième question, il devrait relier les enregistrements sur les entreprises à ceux des données relatives aux marchés publics, exigeant que le même identifiant soit utilisé dans ces deux sources. Dans ces deux questions, des informations pseudonymisées suffiraient. Ces requêtes peuvent générer des questions supplémentaires, telles que Quelles sont les caractéristiques des entreprises présentant un degré élevé de concentration de la propriété ? ou Quelles sont les personnalités politiques impliquées dans ces entreprises ? Dans cette dernière question, les utilisateurs s’intéresseraient à des individus en particulier et ne seraient pas en mesure de répondre à la question au moyen de données pseudonymisées. Ainsi, une journaliste qui étudiait la concentration de la propriété dans les médias arméniens s’est intéressé aux sociétés de télévision arméniennes et a cherché à identifier certains individus exerçant une influence significative sur le paysage médiatique – dans ce cas, les données ne pourraient pas être pseudonymisées pour pouvoir aboutir aux conclusions recherchées. [79]
Étant donné que les requêtes initiales peuvent générer des questions supplémentaires imprévues, associées à un nouvel ensemble de besoins, qui peuvent être différents des besoins initiaux des utilisateurs, l’utilisation des données peut être considérée comme un parcours ponctué d’étapes comprenant diverses pistes de questionnement. En conséquence, les utilisateurs peuvent également être amenés à passer d’une question à une autre et d’une source de données à une autre, si bien qu’il est difficile de prévoir les parcours d’utilisation des données relatives à la PE, et donc les besoins connexes des utilisateurs (voir l’Encadré 7).
Encadré 7. L’utilisation des données sur les bénéficiaires effectifs, un parcours ponctué d’étapes.
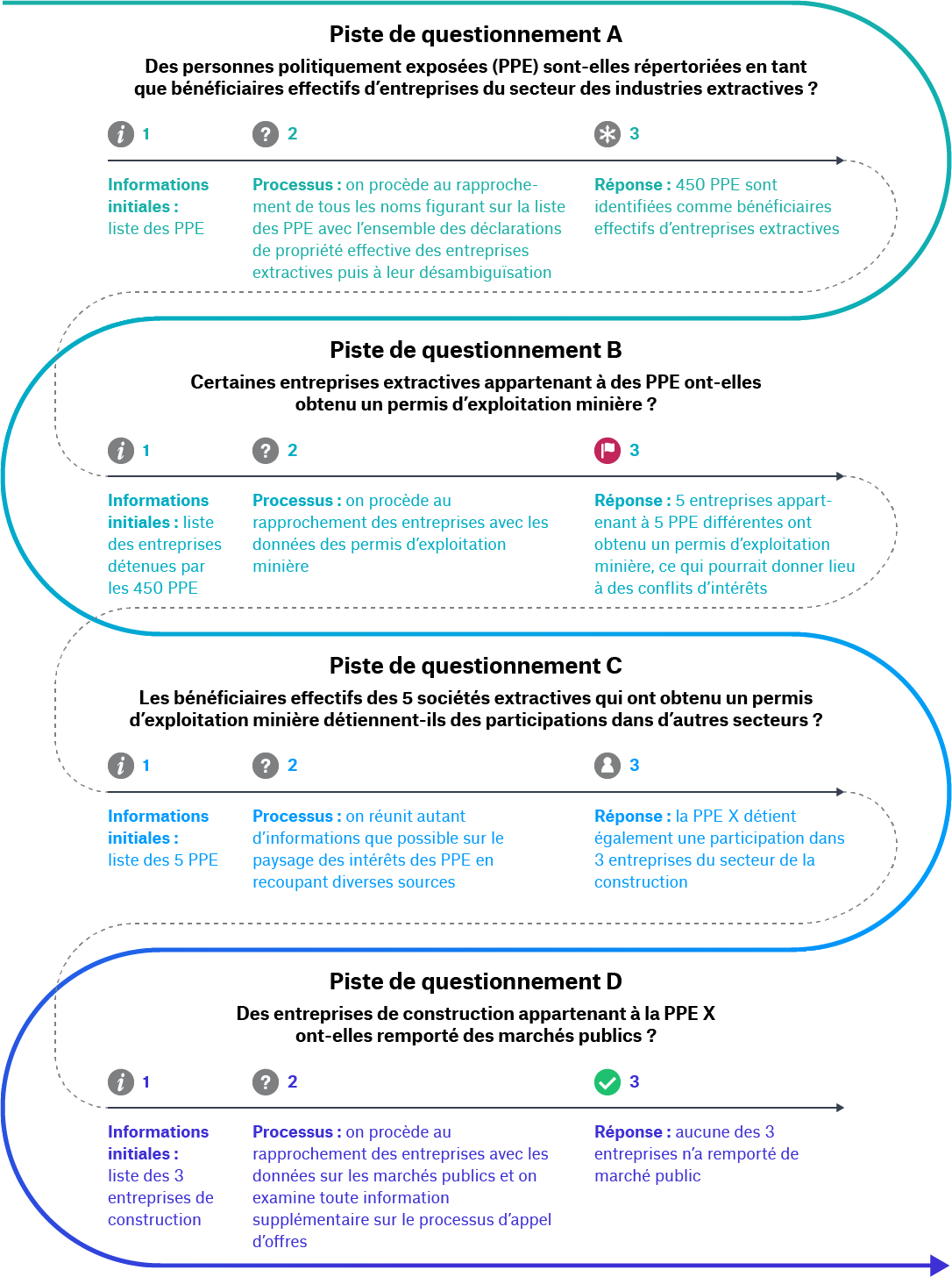
La première piste de questionnement nécessite un traitement à grande échelle. L’utilisateur peut générer des statistiques sur la participation des PPE dans des entreprises extractives (quantitatives) ou identifier des entreprises et des PPE spécifiques sur lesquelles il convient de poursuivre les investigations (qualitatives). À ce stade, l’utilisateur doit associer les individus d’un registre de BE à une liste de PPE.
Après avoir identifié plusieurs centaines de PPE répertoriées comme bénéficiaires effectifs d’entreprises extractives dans les registres de BE, l’utilisateur souhaite déterminer si l’une de ces sociétés a obtenu un permis d’exploitation minière et s’il y a eu de potentiels conflits d’intérêts. [80] Il devra alors combiner les informations relatives à la PE avec les informations sur les permis d’exploitation minière. Le temps et les efforts nécessaires dépendront de l’éventuelle présence, dans ces deux sources d’information, d’un identifiant commun afin de déterminer, par exemple, si les enregistrements relatifs à la Société A figurant dans le registre de BE et les enregistrements relatifs à la Société A figurant dans le registre des permis miniers renvoient à la même entité.
Dans cet exemple, l’utilisateur a identifié des signaux d’alerte concernant des conflits d’intérêts potentiels dans le secteur extractif et souhaite élargir son analyse et vérifier l’éventualité d’un risque similaire dans d’autres secteurs (pistes de questionnement C et D).
Dans la pratique, un utilisateur n’aura presque jamais besoin d’accéder à et de traiter des données d’une seule et unique manière. Cela suggère que, contrairement à la deuxième hypothèse de l’étude, il n’est pas nécessairement impératif ou utile de définir des catégories d’utilisateurs de données pour prendre des décisions sur le contenu ou la structure des informations relatives à la PE. Le fait de disposer d’une vision globale des besoins agrégés des utilisateurs – au-delà des professions exercées par ces derniers – et de s’efforcer d’y répondre dans son ensemble pourrait davantage éclairer les dispositions en matière d’accès qui permettent une utilisation efficace des données.
La majorité des utilisateurs de données sur la PE nécessitent une certaine flexibilité pour accéder aux données et les traiter de façon à permettre différents types d’utilisation. Des dispositions plus restrictives en matière d’accès et d’utilisation entraîneront une limitation des types d’utilisation possibles.
Résultats de l’étude et pistes de recherche future
Les résultats de l’étude peuvent être synthétisés comme suit :
- Les informations relatives à la PE sont exploitées de différentes manières (types d’utilisation), qui déterminent les besoins spécifiques de l’utilisateur, selon la première hypothèse. La combinaison des éléments présentés dans le présent rapport (nature, échelle, étendue et fréquence) aide à identifier les caractéristiques des questions des utilisateurs ainsi qu’à déterminer les types d’utilisation et les besoins associés des utilisateurs en vue de répondre à ces questions.
- Cependant, les types d’utilisation recoupent différents profils d’utilisateurs. Il n’est donc pas pertinent de catégoriser les besoins des utilisateurs sur la seule base des profils d’utilisateurs dans le cadre des décisions concernant les régimes d’accès. En outre, l’utilisation des données correspond souvent à un parcours ponctué d’étapes, qui implique différents types d’utilisation. Compte tenu de son caractère varié et imprévisible, les utilisateurs nécessitent une certaine flexibilité pour accéder aux données et les traiter de façon à permettre différents types d’utilisation. Par conséquent, et contrairement à la deuxième hypothèse, plutôt que de fonder l’accès sur une typologie des types d’utilisation, il est probablement plus percutant de s’appuyer sur un vue d’ensemble de l’éventail des besoins des utilisateurs décrits dans cette étude pour éclairer les décisions en matière d’accès.
Ces conclusions peuvent éclairer la conception et la mise en œuvre de réformes en faveur de la TPE qui favorisent le plus large éventail possible de types d’utilisation, et sont donc plus susceptibles d’aboutir à une utilisation efficace et à un impact concret.
Jusqu’à présent, le débat autour de la question de l’accès a principalement porté sur le caractère publiquement accessible, ou non, des registres, mais il s’agit là d’une fausse dichotomie. [81] Les résultats de l’étude suggèrent de recentrer le discours sur l’accès aux informations relatives à la PE en ne s’interrogeant plus uniquement sur « qui devrait accéder aux données sur la PE », mais en abordant également l’accès à travers le prisme des modalités de traitement des données sur la PE au regard de leur finalité. Cette nouvelle approche implique de s’intéresser aux types d’utilisation les plus susceptibles de faire progresser les objectifs politiques et les besoins qui y sont associés. En associant les modalités de traitement des informations aux besoins et objectifs minimaux des utilisateurs, les dispositions en matière d’accès seront plus conformes aux exigences en matière de protection des données.
L’étude reconnaît que la majorité des utilisateurs de données sur la PE doivent pouvoir jouir d’une grande flexibilité en matière d’accès et de traitement, et invite par conséquent à poursuivre les travaux pour élaborer des recommandations portant sur la conception de régimes d’accès conférant une flexibilité accrue aux utilisateurs. Peut-on assurer ce degré de flexibilité dans des contextes dans lesquels les informations relatives à la PE sont publiquement accessibles ? Au Royaume-Uni, cela semble être le cas, mais il est peu probable qu’il en soit de même partout. Dans d’autres contextes, il peut être nécessaire partout. Dans d’autres contextes, il peut être nécessaire de mettre en place des garanties en matière de protection de la vie privée et des données pour permettre un accès et une utilisation flexibles, en veillant à ce que ces garanties n’empêchent pas d’utiliser efficacement les informations en question. Les pays devraient étudier comment les systèmes d’accès à pleasures niveaux peuvent se fonder sur la base de niveaux de flexibilité dans les modalités de traitement de l’information (par ex. API, recherche selon une gamme de critères) en plus de la quantité d’information accessible. Si l’accès sur la base de l’intérêt légitime peut être appliqué de façon efficace et fournit des données structurées de haute qualité avec un large éventail d’attributs en masse ou via une API, il est possible que cette option produise un impact plus important que lorsque les utilisateurs passent par un portail public proposant des fonctionnalités de recherche limitées. Des travaux supplémentaires devront être entrepris afin de déterminer comment parvenir à cet équilibre, en accordant une attention particulière aux dispositions relatives à l’accès, à l’utilisation des données ainsi qu’à la question de l’impact.
Dans cette optique, Open Ownership envisage de traduire les besoins des utilisateurs identifiés dans cette étude en termes de caractéristiques et fonctionnalités spécifiques pour appuyer la conception des systèmes qui collectent, stockent et partagent les informations relatives à la PE. Cela permettra également aux responsables de la mise en place de registres de propriété effective d’évaluer si leur registre permet aux utilisateurs de données de répondre à leurs questions et de contribuer ainsi à la réalisation des objectifs politiques énoncés.
Une autre problématique essentielle se pose sur les moyens de relever les défis associés à l’accès et au traitement des informations relatives à la PE provenant de plusieurs juridictions, y compris pour les autorités chargées de l’application de la loi, par exemple. Le rôle des accords internationaux et régionaux de partage des données ainsi que d’autres solutions potentielles méritent d’être explorés davantage.
La présente étude a soulevé un certain nombre de questions qui offrent des pistes de recherche future potentielle. Par exemple :
- Le recours à des intermédiaires de données permet de résoudre les problèmes de base touchant à leur utilisation et fournissent des fonctionnalités et des outils avancés pour permettre des analyses plus poussées. Ces intermédiaires jouent un rôle essentiel dans l’écosystème d’utilisation des données relatives à la PE. Cela soulève d’importantes questions quant aux capacités techniques et au rapport coût-efficacité pour les gouvernements qui développent leurs propres outils d’utilisation des données. Ces questions sont également pertinentes dans le contexte du développement des API, signalé par de nombreux participants à l’étude comme un paramètre essentiel en faveur d’une utilisation efficace des données. Comment les responsables de registres disposant de capacités techniques et financières moindres peuvent-ils répondre efficacement aux besoins des utilisateurs ? Le coût que représentent les prestataires commerciaux peut-il entraîner des inégalités dans l’utilisation des données ? Compte tenu de leur rôle central en faveur de l’utilisation des données par les utilisateurs finaux, cette question appelle aussi à s’interroger sur les prestations d’accès et de traitement des données au profit des utilisateurs intermédiaires. Des recherches plus poussées sont nécessaires afin d’étudier le rôle potentiel des partenariats public-privé dans l’amélioration de l’utilisation des données sur la PE.
- L’utilisation de ces données implique généralement la compréhension des relations entre les sujets à travers différentes sources d’information et juridictions. Dès lors que de nombreux participants à l’étude ont déclaré éprouver des difficultés à cet égard à l’heure actuelle, beaucoup plébiscitent les plateformes qui centralisent les informations issues de sources diverses et contribuent à une meilleure compréhension des réseaux de propriété. À l’heure actuelle, le volume d’informations contenues dans les registres d’actifs n’est pas suffisant pour établir aisément si les enregistrements qui y figurent portent sur le même sujet que les enregistrements des registres sur la PE. Dès lors, il pourrait être pertinent de définir un ensemble commun minimum de renseignements à faire figurer dans les registres d’actifs nationaux. [82] Il convient également d’explorer comment utiliser les informations sur les actionnaires en tant que source d’information plus fiable en vue d’améliorer la compréhension des réseaux de propriété, réduire les contraintes de conformité et vérifier les déclarations de BE.
- Enfin, cette étude jette les bases d’un processus visant à évaluer de manière systématique et proactive dans quelle mesure les décisions relatives à la conception des politiques et des systèmes influent sur l’efficacité d’utilisation des données et, à terme, sur l’impact des réformes en faveur de la TPE. Des travaux supplémentaires sont nécessaires afin de définir un ensemble d’indicateurs sur lequel s’appuiera cet exercice de mesure.
Notes de bas de page
[7] Open Ownership, Les principes d’Open Ownership.
[8] Entretien n° 3.
[9] Entretien n° 18.
[10] « About OCCRP Aleph », OCCRP, Aleph, n.d., https://aleph.occrp.org/pages/about.
[11] Entretien n° 28 ; entretien n° 7.
[12] Entretien n° 22.
[13] Entretien n° 22 ; entretien n° 29. Dans le contexte européen, le réseau NEBOT (Network of Experts on Beneficial Ownership Transparency) a donné un aperçu de divers registres nationaux de bénéficiaires effectifs, qui a également mis en évidence les problèmes posés par les fonctionnalités de recherche limitées. Voir : Adriana Fraiha Granjo, Maíra Martini et Gabriel Sipos, NEBOT Paper Five – Beneficial ownership registers in the EU : Progress so far and the way forward (Commission européenne, Direction générale de la stabilité financière, des services financiers et de l’union des marchés des capitaux (FISMA) – Office des publications de l’Union européenne, 2023), https://images.transparencycdn.org/images/NEBOT-Paper-5.pdf.
[14] Entretien n° 12.
[15] Entretien n° 25.
[16] Entretien n° 13.
[17] Kadie Armstrong, Établir des registres vérifiables des déclarations de propriété effective (Initiative pour la Transparence dans les Industries Extractives (ITIE) et Open Ownership, 2022), https://www.openownership.org/en/publications/building-an-auditable-record-of-beneficial-ownership/.
[18] Entretien n° 23.
[19] Entretien n° 13 ; entretien n° 12. Voir : Julie Rialet, Use and impact of public beneficial ownership registers: Denmark (Open Ownership, 2023), https://www.openownership.org/en/publications/use-and-impact-of-public-beneficial-ownership-registers-denmark/.
[20] Entretien n° 25.
[21] Entretien test avec Siiri Grabbi, responsable Sanctions/Lutte contre le financement du terrorisme, Coop Pank AS, Estonie, 29 octobre 2024. Voir : Miranda Evans, « Lessons from building a prototype single-search tool for beneficial ownership registers », Open Ownership, 7 mars 2025, https://www.openownership.org/en/blog/lessons-from-building-a-prototype-single-search-tool-for-beneficial-ownership-registers/.
[22] Evans, « Lessons from building a prototype single-search tool for beneficial ownership registers ».
[23] Entretien n° 34.
[24] Competition and Markets Authority (CMA), The State of UK Competition (CMA, 2022), https://assets.publishing.service.gov.uk/media/627e6cf6d3bf7f052d33b0ae/State_of_Competition.pdf.
[25] CMA, « Appendice A : Concentration », en State of UK Competition, (CMA, 2022), paragr. 89, https://assets.publishing.service.gov.uk/media/626ab6c4d3bf7f0e7f9d5a9b/220426_Annex_-State_of_Competition_Appendices_FINAL.pdf.
[26] Kadie Armstrong et Stephen Abbott Pugh, Using reliable identifiers for corporate vehicles in beneficial ownership data (ITIE et Open Ownership, 2023), https://www.openownership.org/en/publications/using-reliable-identifiers-for-corporate-vehicles-in-beneficial-ownership-data/.
[27] Alanna Markle, Sufficiently detailed beneficial ownership information (Open Ownership, 2025), https://www.openownership.org/en/publications/sufficiently-detailed-beneficial-ownership-information/.
[28] Banque des règlements internationaux (BRI), Report to the G20 : Harmonised ISO 20022 data requirements for enhancing cross-border payments (BIS, 2023), https://www.bis.org/cpmi/publ/d218.pdf.
[29] Entretien test avec un expert indépendant de la criminalité financière, Danemark, 11 novembre 2024. Voir : Evans, « Lessons from building a prototype single-search tool for beneficial ownership registers ».
[30] Entretien avec Mihály Fazekas, professeur agrégé à l’Université d’Europe centrale et fondateur du Government Transparency Institute ; Antoninia Volkotrub, analyste financière pour l’Anti-Corruption Action Center, Ukraine ; et Irene Tello Arista, coprésidente d’Action4Justice et chercheuse doctorante à l’Université d’Europe centrale, 1 décembre 2023.
[31] Centre for Finance, Innovation and Technology (CFIT), Fighting Economic Crime Through Enhanced Verification: Interim paper from CFIT’s second coalition (CFIT, 2024), https://cfit.org.uk/wp-content/uploads/2024/12/CFIT-Economic-Crime-Coalition-Interim-White-Paper-1.pdf.
32 « Identité numérique européenne », Commission européenne, n.d., https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/european-digital-identity_en.
[33] Entretien n° 19.
[34] Entretien n° 19.
[35] Entretien n° 18.
[36] Entretien n° 23.
[37] Entretien n° 13.
[38] Entretien n° 25.
[39] Entretien n° 19.
[40] Pour de plus amples informations, voir : Sadaf Lakhani, The use of beneficial ownership data by private entities (Open Ownership, 2022), https://www.openownership.org/en/publications/the-use-of-beneficial-ownership-data-by-private-entities/.
[41] Entretien n° 20 ; entretien n° 12.
[42] Entretien n° 29.
[43] Entretien n° 27 ; entretien n° 20.
[44] Entretien n° 12 ; entretien n° 27.
[45] Entretien n° 34.
[46] Sara Brimbeuf, Maíra Martini, Florian Hollenbach et David Szakonyi, Behind A Wall : Investigating Company and Real Estate Ownership in France (Transparency International France et Anti-Corruption Data Collective, 2023), https://images.transparencycdn.org/images/2023-Report-Behind-a-Wall-English.pdf.
[47] Rialet, « Closing the loop ».
[48] Entretien test avec Ben Cowdock, responsable principal Investigations, Transparency International Royaume-Uni, 27 novembre 2024. Voir : Evans, « Lessons from building a prototype single-search tool for beneficial ownership registers ».
[49] Entretien n° 21.
[50] Entretien n° 20 ; entretien n° 29 ; entretien n° 26.
[51] « Regulatory penalties for global financial institutions surge 31% in H1 2024 », Fenergo, 14 août 2024, https://resources.fenergo.com/newsroom/regulatory-penalties-for-global-financial-institutions-surge-31-in-h1-2024; GAFI, Recommandations 10.3 et 29.3, Méthodologie d’ évaluation de la conformité technique aux Recommandations du GAFI et de l’efficacité des systèmes de LBC/FT (GAFI, mise à jour 2023), 46, 85, https://www.fatf-gafi.org/content/dam/fatf-gafi/methodology/FATF%20Methodology%2022%20Feb%202013.pdf.coredownload.pdf; Egmont Group, Egmont Group Of Financial Intelligence Units : Principles For Information Exchange Between Financial Intelligence Units (Egmont Group, mise à jour 2022), https://egmontgroup.org/wp-content/uploads/2013/10/2.-Principles-Information-Exchange-Revised-May-2022-01.pdf.
[52] Entretien n° 13.
[53] Entretien n° 28.
[54] Entretien n° 2.
[55] Open Ownership, « Screening mining and petroleum licences with beneficial ownership information », atelier de renforcement des capacités techniques, Ghana, 8-12 juillet 2024; entretien n° 10.
[56] Entretien n° 36. Voir l’étude de cas sur la PE au Danemark : Rialet, Use and impact of public beneficial ownership registers : Denmark, 10.
[57] Entretien n° 21.
[58] Entretien n° 16.
[59] Entretien n° 33.
[60] Brimbeuf et al., Behind A Wall.
[61] Irene Tello Arista, Mihály Fazekas et Antonina Volkotrub, Using beneficial ownership data for large-scale risk assessment in public procurement: The example of 6 European countries (Government Transparency Institute, 2024), https://www.govtransparency.eu/wp-content/uploads/2024/07/Arista-Fazekas-Volkotrub_BO-CRI_GTI_WP_2024.pdf.
[62] Entretien n° 24.
[63] Entretien n° 21.
[64] Entretien n° 3.
[65] Entretien test avec Ben Cowdock, responsable principal Investigations, Transparency International Royaume-Uni, 27 novembre 2024. Voir : Evans, « Lessons from building a prototype single-search tool for beneficial ownership registers ».
[66] Entretien n° 3.
[67] Entretien n° 4.
[68] Entretien n° 12.
[69] Adam Travis, « The Organization of Neglect : Limited Liability Companies and Housing Disinvestment », American Sociological Review 84, n° 1 (2019) : 142-170, https://doi.org/10.1177/0003122418821339; Rachel Holliday Smith, « More Money ? Pushy Landlord ? Your Emergency Rental Assistance Program (ERAP) Questions Answered », The City, 7 mars 2022, https://www.thecity.nyc/2022/03/07/new-york-city-landlord-emergency-rental-assistance-program-erap-questions-answered/.
[70] Ce type de question est utile pour évaluer la qualité des données et suggérer des axes d’amélioration aux autorités chargées de la mise en œuvre des réformes en faveur de la TPE. Open Ownership a mené et soutenu ce type d’analyse. Voir, par exemple, cette publication à venir en collaboration avec le Tax Justice Network : Maria Jofre et Andres Knobel, Insights from the United Kingdom People with significant control register (Open Ownership et Tax Justice Network, à venir en 2025) ; GAFI, Rapport sur le niveau d’efficacité et de conformité aux normes du GAFI (GAFI, 2022), 33, https://www.fatf-gafi.org/content/dam/fatf-gafi/reports/Report-on-the-State-of-Effectiveness-Compliance-with-FATF-Standards.pdf.coredownload.pdf.
[71] Egmont Group, « Case 3 : Nigeria’s former oil minister charged after $20 billion goes missing from petroleum agency — Nigeria FIU », Best Egmont Cases : Financial Analysis Cases 2021-2023 (Egmont Group, 2024), 15-20, https://egmontgroup.org/wp-content/uploads/2024/09/EGMONT_2021-2023-BECA-III_FINAL.pdf.
[72] Delgermaa Boldbaatar (Mongolian Data Club) et Erdenechimeg Dashdorj (Open Society Forum), « Digging out data to shine a light on public buying in Mongolia », Open Contracting Partnership, 11 octobre 2023, https://www.open-contracting.org/2023/10/11/digging-out-data-to-shine-a-light-on-public-buying-in-mongolia/.
[73] Ц.Мягмарбаяр, Б.Энхзаяа, Ц.Энхдулам, and А.Маралмаа,“Тэнцүү олгосон нэртэй с зөвшөөрлийн ард сингапур, хятад ноёд туйлж байна”, Polit.mn, 28 avril 2023, https://www.polit.mn/a/101369.
[74] Б.Ариунзаяа, “МЭДЛЭГИЙН ГРАФ: Сонгуулийн уралдаанд №1-т сойсон Г.Лувсанжамцын ‘шүдийг шинжье’”, Datastory, 23 juin 2024, http://datastory.mn/article/46; Б.Ариунзаяа, “Эрчим хүчний сэргэлтийн илгээлтийн эзэн М.Энхцэцэгийн авсан тендэр ₮16.3 тэрбум”, Datastory, 27 juin 2024, http://datastory.mn/article/47.
[75] Joining the Dots, page d’accueil, Directorio Legislativo, n.d., https://peps.directoriolegislativo.org/.
[76] Rialet, Use and impact of public beneficial ownership registers: Denmark, 10.
[77] Entretien n° 21.
[78] Entretien n° 23.
[79] Mariam Tashchyan, « Ովքե՞ր են հետուստաընկերությունների իրական շահառուները. հայտարարագրվածն ու «դուրս մնացածը» », CivilNet, 27 décembre 2022, https://www.civilnet.am/news/687511/.
[80] L’Anti-Corruption Action Centre (AntAC) a par exemple mené ce type d’analyse aux fins d’identifier les PPE qui détenaient en dernier lieu une grande partie des permis dans le secteur extractif en Ukraine. Voir : AntAC, Who owns oil and gas fields of Ukraine ? – Analytical report. Part 1 (AntAC, 2018), https://antac.org.ua/en/news/11-politically-exposed-persons-own-a-quarter-of-all-permits-for-extraction-of-oil-and-gas-in-ukraine-report/.
[81] Tymon Kiepe, « Striking a balance : Towards a more nuanced conversation about access to beneficial ownership information », Open Ownership, 18 octobre 2023, https://www.openownership.org/en/blog/striking-a-balance-towards-a-more-nuanced-conversation-about-access-to-beneficial-ownership-information/.
[82] Les données structurées désignent des informations hautement organisées suivant un modèle prédéfini. Voir : Tymon Kiepe, « Solving the international information puzzle of beneficial ownership transparency », Open Ownership, 17 juin 2024, https://www.openownership.org/en/blog/solving-the-international-information-puzzle-of-beneficial-ownership-transparency/.